




 廣告
廣告





















































首頁(yè) > 汽車(chē)技術(shù) > 正文
利用魯棒控制實(shí)現(xiàn)深度強(qiáng)化學(xué)習(xí)駕駛策略的遷移
2019-04-09 11:30:04· 來(lái)源:ControlPlusAI

從運(yùn)動(dòng)規(guī)劃和控制的角度來(lái)看,盡管傳統(tǒng)的基于模型的算法已經(jīng)可以幫助我們完成在相對(duì)簡(jiǎn)單可控的環(huán)境下的駕駛?cè)蝿?wù),如何在復(fù)雜場(chǎng)景(例如涉及多車(chē)進(jìn)行復(fù)雜交互的場(chǎng)
從運(yùn)動(dòng)規(guī)劃和控制的角度來(lái)看,盡管傳統(tǒng)的基于模型的算法已經(jīng)可以幫助我們完成在相對(duì)簡(jiǎn)單可控的環(huán)境下的駕駛?cè)蝿?wù),如何在復(fù)雜場(chǎng)景(例如涉及多車(chē)進(jìn)行復(fù)雜交互的場(chǎng)景)下安全高效的通行仍然是亟待解決的問(wèn)題。
自動(dòng)駕駛無(wú)疑是當(dāng)下最熱門(mén)的話(huà)題之一,無(wú)論是工業(yè)界還是學(xué)術(shù)界都在不斷探索實(shí)現(xiàn)自動(dòng)駕駛的方法。從運(yùn)動(dòng)規(guī)劃和控制的角度來(lái)看,盡管傳統(tǒng)的基于模型的算法已經(jīng)可以幫助我們完成在相對(duì)簡(jiǎn)單可控的環(huán)境下的駕駛?cè)蝿?wù),如何在復(fù)雜場(chǎng)景(例如涉及多車(chē)進(jìn)行復(fù)雜交互的場(chǎng)景)下安全高效的通行仍然是亟待解決的問(wèn)題。我們認(rèn)為利用深度強(qiáng)化學(xué)習(xí)(Deep Reinforcement Learning),尤其是無(wú)模型(model-free)的強(qiáng)化學(xué)習(xí)算法,來(lái)學(xué)習(xí)復(fù)雜場(chǎng)景下的駕駛策略是一個(gè)值得探索的方向。通過(guò)在訓(xùn)練階段的大量探索,強(qiáng)化學(xué)習(xí)算法可以在訓(xùn)練環(huán)境中采集不同情況下的數(shù)據(jù),從而針對(duì)各種情況對(duì)策略進(jìn)行優(yōu)化,最終獲得在訓(xùn)練環(huán)境中相對(duì)理想的策略。利用這樣的方式,我們可以避免對(duì)復(fù)雜場(chǎng)景的建模,得到可以在線(xiàn)上快速運(yùn)算的規(guī)劃及控制策略。
然而,強(qiáng)化學(xué)習(xí)存在許多現(xiàn)實(shí)問(wèn)題,其中最重要的問(wèn)題之一就是強(qiáng)化學(xué)習(xí)缺乏足夠的魯棒性(Robustness)。一旦環(huán)境發(fā)生變化,出現(xiàn)訓(xùn)練環(huán)境沒(méi)有出現(xiàn)的情況,原本在訓(xùn)練環(huán)境中表現(xiàn)優(yōu)異的策略模型往往無(wú)法正確應(yīng)對(duì)。而自動(dòng)駕駛車(chē)輛需要在各種復(fù)雜交通狀況下行駛,我們無(wú)法保證在訓(xùn)練中囊括所有的場(chǎng)景。另一方面,出于安全以及訓(xùn)練效率方面的考慮,駕駛策略往往需要在仿真環(huán)境中訓(xùn)練,這更加劇了訓(xùn)練環(huán)境和實(shí)際工作場(chǎng)景間的差距,使得強(qiáng)化學(xué)習(xí)生成的駕駛策略無(wú)法在實(shí)際的自動(dòng)駕駛車(chē)輛上部署。為了解決魯棒性問(wèn)題,許多研究者開(kāi)始使用遷移學(xué)習(xí)的方法(Transfer Learning),使得在訓(xùn)練好的策略模型可以在新的環(huán)境中直接使用(zero-shot),或是經(jīng)過(guò)快速的微調(diào)后可以在新的場(chǎng)景下達(dá)到理想效果(one-shot/few shot)。
在本文中,我們所關(guān)注的問(wèn)題是駕駛策略對(duì)車(chē)輛動(dòng)力學(xué)模型變化的魯棒性,比如模型參數(shù)(如質(zhì)量,轉(zhuǎn)動(dòng)慣性,輪胎模型參數(shù)等等)的變化以及外界的擾動(dòng)如道路傾角和側(cè)向風(fēng)導(dǎo)致加載在車(chē)輛上的側(cè)向力。我們希望可以將訓(xùn)練好的駕駛策略直接應(yīng)用在相對(duì)于訓(xùn)練環(huán)境的車(chē)輛有一定變化的車(chē)輛上面,比如仿真環(huán)境中的不同車(chē)輛或是真實(shí)車(chē)輛,并達(dá)到和在訓(xùn)練環(huán)境中時(shí)相同的效果。為了達(dá)到這個(gè)目標(biāo),我們提出了基于魯棒控制的駕駛策略遷移框架(RL-RC)。我們?cè)诜抡娴挠?xùn)練環(huán)境(source domain)中訓(xùn)練初始的強(qiáng)化學(xué)習(xí)策略,隨后將訓(xùn)練的強(qiáng)化學(xué)習(xí)策略應(yīng)用在目標(biāo)環(huán)境(target domain)中。
我們假設(shè)二者的區(qū)別僅在于控制車(chē)輛的動(dòng)力學(xué)模型有一定程度的差異,并且我們可以獲取訓(xùn)練環(huán)境中車(chē)輛的動(dòng)力學(xué)模型。在遷移的過(guò)程中,我們假設(shè)相同的行駛軌跡在訓(xùn)練環(huán)境和目標(biāo)環(huán)境中有著相同的可行性(Feasibility)和最優(yōu)性(Optimality),這在二者中控制車(chē)輛雖然不同但類(lèi)似的情況下是合理的假設(shè)。因此,我們可以直接利用在目標(biāo)環(huán)境中檢測(cè)的信息,在訓(xùn)練環(huán)境中建立相同的場(chǎng)景,并利用駕駛策略向前仿真一段時(shí)間,從而得到在訓(xùn)練環(huán)境中未來(lái)一段時(shí)間內(nèi)車(chē)輛行駛的軌跡。在目標(biāo)環(huán)境中的車(chē)輛上,我們利用已知的車(chē)輛動(dòng)力學(xué)模型信息,設(shè)計(jì)魯棒控制器來(lái)控制車(chē)輛追蹤生成的參考軌跡。
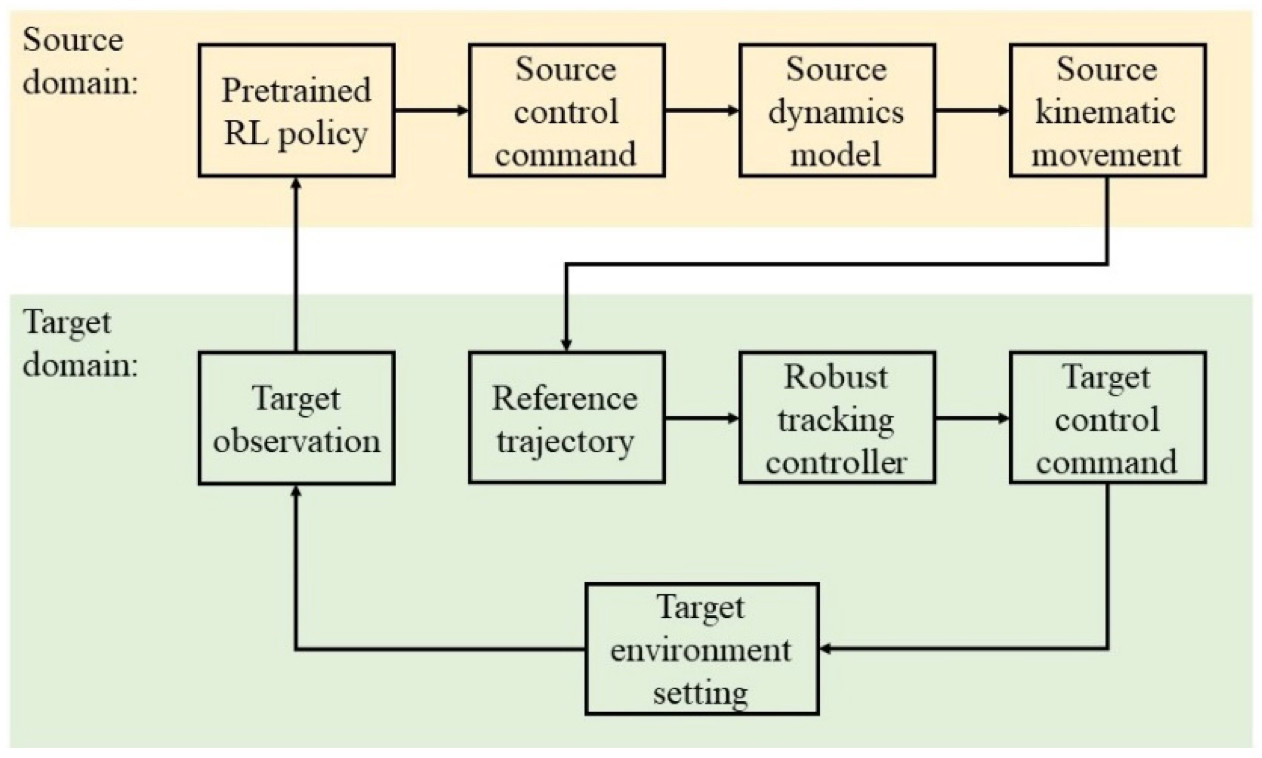
RL-RC 策略遷移框架示意圖
在這一框架中,我們將軌跡作為可直接遷移的中間變量,增加了遷移過(guò)程的可解釋性,并且避免了在目標(biāo)環(huán)境中對(duì)策略的調(diào)整,提高了安全性。利用魯棒控制理論,我們可以保障底層追蹤控制器在存在擾動(dòng)情況下的效果,更加有效地提高遷移框架的魯棒性。在實(shí)際的實(shí)驗(yàn)中,我們用策略梯度(Policy Gradient)算法PPO訓(xùn)練駕駛策略完成車(chē)道保持、換道以及避障任務(wù),在目標(biāo)環(huán)境中,我們?cè)O(shè)計(jì)了基于Disturbance Observer (DOB)的控制器實(shí)現(xiàn)軌跡追蹤。我們?cè)诓煌姆抡姝h(huán)境之間,取得了良好的策略遷移效果。在車(chē)輛模型參數(shù)有一定程度的隨機(jī)變化或是存在外加側(cè)向力的情況下,RL-RC方法可以在目標(biāo)環(huán)境中保持訓(xùn)練環(huán)境中的表現(xiàn),順利完成指定任務(wù)。而原本的駕駛策略在目標(biāo)環(huán)境中的表現(xiàn)有著顯著的下降。在之后的研究中,我們將嘗試把RL-RC方法應(yīng)用在從仿真環(huán)境到真實(shí)車(chē)輛的策略遷移,用實(shí)車(chē)實(shí)驗(yàn)進(jìn)一步驗(yàn)證遷移方法的可行性。同時(shí),改進(jìn)RL策略以及魯棒控制器,使得遷移過(guò)程更加安全可靠,實(shí)現(xiàn)更加復(fù)雜場(chǎng)景下的策略遷移。
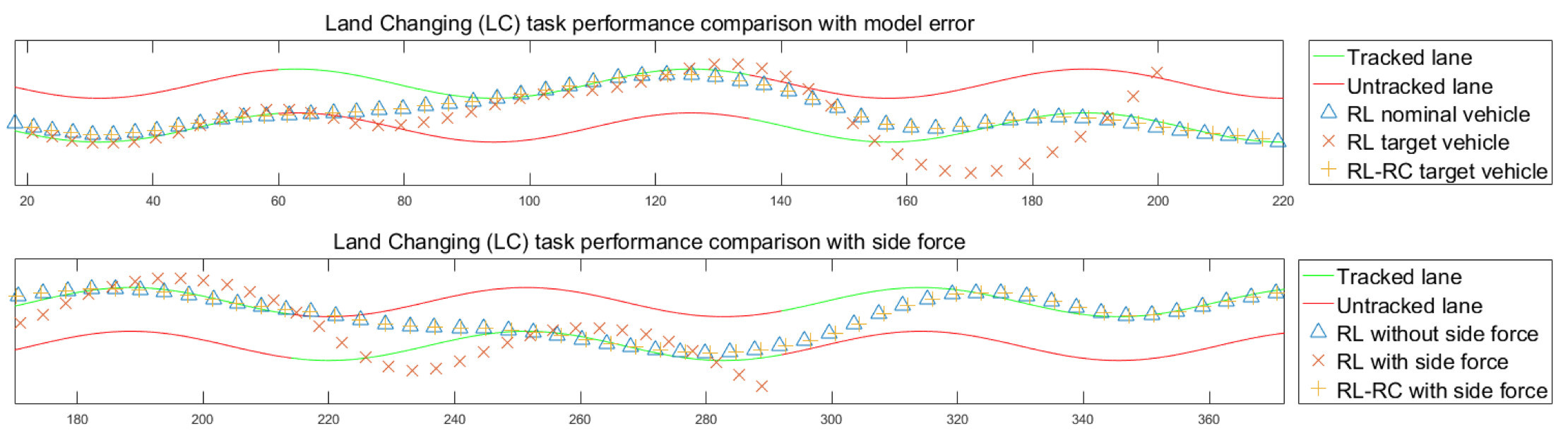
RL-RC方法可以控制車(chē)輛在目標(biāo)環(huán)境中實(shí)現(xiàn)與訓(xùn)練時(shí)幾乎相同的行駛軌跡,而原本的RL策略在模型參數(shù)有變化或是存在擾動(dòng)的情況下會(huì)失去穩(wěn)定性,無(wú)法完成任務(wù)
(具體方法及更詳盡的分析請(qǐng)參考論文)
Zhuo Xu*, Chen Tang*, and M. Tomizuka, “Zero-shot Deep Reinforcement Learning Driving Policy Transfer for Autonomous Vehicles based on Robust Control”, in IEEE Intelligent Transportation System Conference (ITSC), Nov. 2018. Best paper finalist.
https://arxiv.org/abs/1812.03216
點(diǎn)贊 0 反對(duì) 0 舉報(bào) 0
收藏 0
評(píng)論 0 分享 63



 廣告
廣告 編輯推薦




最新資訊
-
聯(lián)合國(guó)法規(guī)R60對(duì)兩輪車(chē)操縱件與指示裝置的
2026-03-04 12:08
-
標(biāo)準(zhǔn)立項(xiàng)|《汽車(chē)異種材料鉚接接頭拉伸性能
2026-03-04 11:40
-
“汽車(chē)大角度座椅 第1部分:通用要求”將有
2026-03-04 11:39
-
“汽車(chē)大角度座椅 第2部分:可靠性要求”將
2026-03-04 11:39
-
電池耐久評(píng)價(jià)開(kāi)始從“電池單體性能指標(biāo)”轉(zhuǎn)
2026-03-04 11:38
