




 廣告
廣告





















































Tesla AutoPilot 純視覺(jué)方案解析
2021-12-19 11:18:21· 來(lái)源:汽車ECU開發(fā)

2021年5月,馬斯克宣布Autopilot的視覺(jué)系統(tǒng)現(xiàn)在已經(jīng)足夠強(qiáng)大,可以在沒(méi)有毫米波雷達(dá)的情況下單獨(dú)使用。緊接著特斯拉官網(wǎng)做出更新,在其車輛的傳感器介紹頁(yè)面也取
2021年5月,馬斯克宣布Autopilot的視覺(jué)系統(tǒng)現(xiàn)在已經(jīng)足夠強(qiáng)大,可以在沒(méi)有毫米波雷達(dá)的情況下單獨(dú)使用。緊接著特斯拉官網(wǎng)做出更新,在其車輛的傳感器介紹頁(yè)面也取消了毫米波雷達(dá)的圖示。
根據(jù) Karpathy——CV界華人大佬的Fei-Fei Li的學(xué)生Andrej Karpathy博士的說(shuō)法,相機(jī)比雷達(dá)好100倍,所以雷達(dá)不會(huì)給融合帶來(lái)太多影響,有時(shí)雷達(dá)甚至?xí)骨闆r變得更糟。
2021年8月特斯拉的Day上,Karpathy博士對(duì)Autopilot的視覺(jué)方案做了詳細(xì)的講解。其核心模板叫HydraNet,內(nèi)部細(xì)節(jié)設(shè)計(jì)非常具有啟發(fā)性,下面一起來(lái)看看。
要理解這個(gè)方案,首先需明確一下Autopilot視覺(jué)系統(tǒng)的輸入和輸出。

圖1,Tesla視覺(jué)感知系統(tǒng)的輸入和輸出
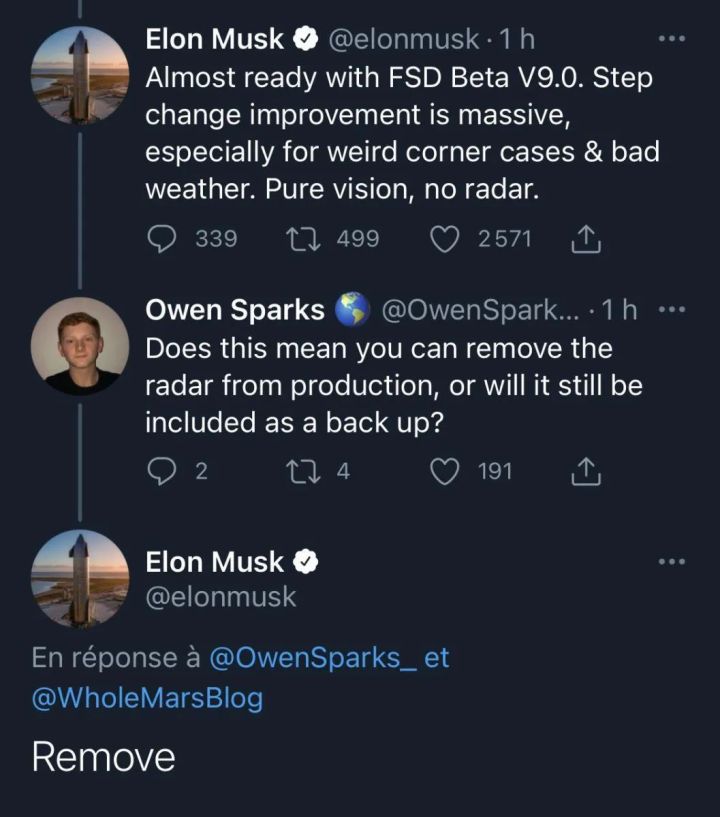
Autopilot的視覺(jué)系統(tǒng)的傳感器由環(huán)繞車身的8個(gè)攝像頭組成,分別為前視3目:負(fù)責(zé)近、中遠(yuǎn)3種不同距離和視角的感知;側(cè)后方2目,側(cè)前方2目,以及后方1目,完整覆蓋360度場(chǎng)景,每個(gè)攝像頭采集分辨率為1280 × 960、12Bit、 36Hz的RAW格式圖像,對(duì)車身周邊環(huán)境的探測(cè)距離最遠(yuǎn)可達(dá)250m。
攝像頭收集的視覺(jué)信息經(jīng)過(guò)一系列神經(jīng)網(wǎng)絡(luò)模型的處理,最終直接輸出用于規(guī)劃和智駕系統(tǒng)3D場(chǎng)景下的 ”Vector Space”。
圖2 Tesla車載相機(jī)布置方式
Tesla的自動(dòng)駕駛感知算法經(jīng)過(guò)了多個(gè)版本迭代,應(yīng)用到了近期的FSD中。我們首先介紹一下最初的HydraNet。
HydraNet
HydraNet以分辨率為1280×960、12-Bit、36Hz的RAW格式圖像作為輸入,采用RegNet作為Backbone,并使用BiFPN構(gòu)建多尺度f(wàn)eature map,然后再在此基礎(chǔ)上添加task specific的Heads。
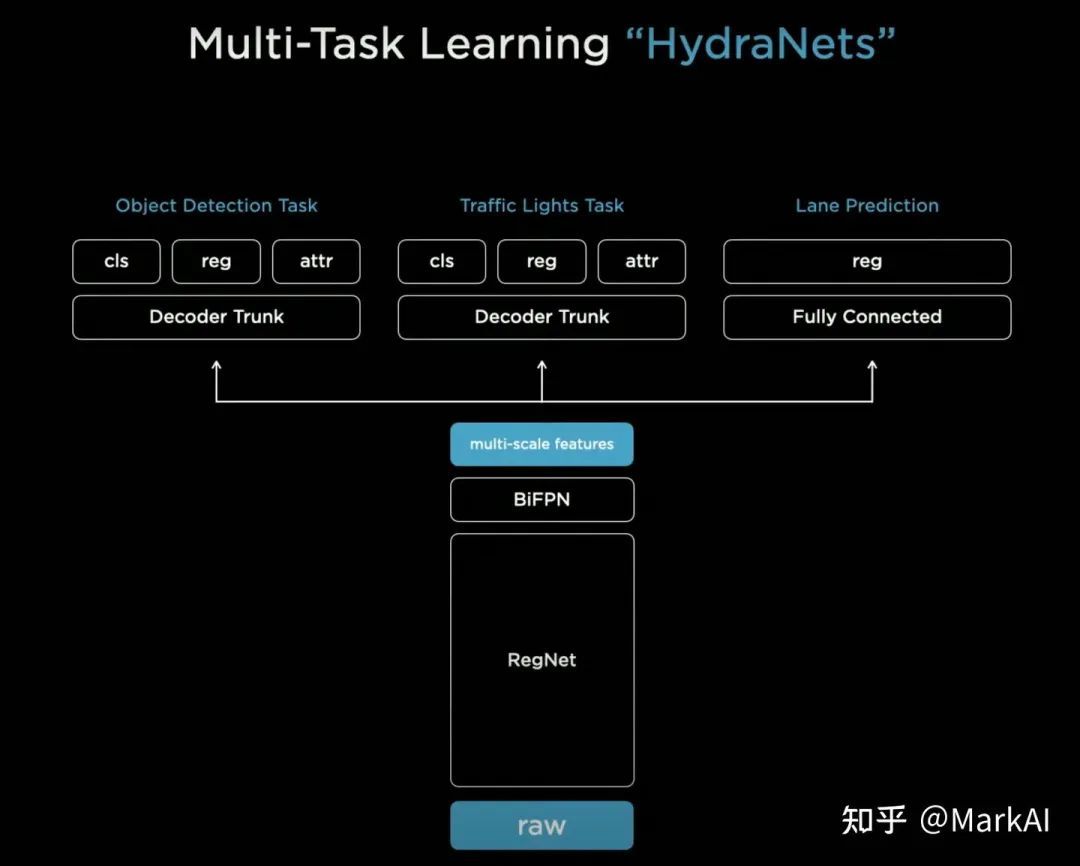
圖3 HydraNet模型結(jié)構(gòu)
熟悉目標(biāo)檢測(cè)或是車道線檢測(cè)的讀者會(huì)發(fā)現(xiàn),初代HydraNet的各部分都比較普通,共享Backbone和BiFPN可以在很大程度上節(jié)省在部署時(shí)的算力需求,也算是業(yè)界比較常見(jiàn)的。
但是,Tesla卻把這樣的結(jié)構(gòu)玩出了花來(lái),主要帶來(lái)以下三點(diǎn)好處:
1、預(yù)測(cè)非常高效:共享特征避免了大量重復(fù)的計(jì)算;
2、解耦每個(gè)子任務(wù):每個(gè)子任務(wù)可在backbone的基礎(chǔ)上進(jìn)行fine-tuning,或是修改,而不影響其他子任務(wù)。
3、加速:訓(xùn)練過(guò)程中可將feature緩存,這樣fine-tuning時(shí)可以只使用緩存的feature來(lái)fine-tune模型的head,而無(wú)需重復(fù)計(jì)算。
從上述可以看出,HydraNet的實(shí)際訓(xùn)練流程為先端到端的訓(xùn)練整個(gè)模型,然后使用緩存的feature分別訓(xùn)練每個(gè)子任務(wù),再端到端地訓(xùn)練整個(gè)模型,以此循環(huán)迭代。
就這樣,一個(gè)普通的模型就被Tesla挖掘到了極致,模型訓(xùn)練中一切可以共享的都進(jìn)行共享,減少不必要的計(jì)算開銷。
同時(shí)我們也容易發(fā)現(xiàn),該模型如果僅使用單相機(jī)圖像作為輸入,會(huì)有很大盲區(qū),只能用于很簡(jiǎn)單的輔助駕駛?cè)蝿?wù),例如車道保持等,并且這還需要借助其他傳感器(超聲波雷達(dá)、毫米波雷達(dá)等)來(lái)降低風(fēng)險(xiǎn)。
更復(fù)雜的自動(dòng)駕駛?cè)蝿?wù)(城市輔助、自主變道等)需要多相機(jī)的圖像作為感知系統(tǒng)的輸入,同時(shí)感知系統(tǒng)的預(yù)測(cè)結(jié)果需要轉(zhuǎn)換到三維空間中的車體坐標(biāo)系下,才能輸入到規(guī)劃和控制系統(tǒng)用以規(guī)劃駕駛行為。
相比單相機(jī),多相機(jī)輸入不是簡(jiǎn)單的針對(duì)多個(gè)相機(jī)的圖像輸入分別預(yù)測(cè),然后投影到車體坐標(biāo)系下就可以,而需整合多個(gè)相機(jī)的感知結(jié)果,再投影到車體坐標(biāo)系。這是一個(gè)很復(fù)雜的工程問(wèn)題。
針對(duì)這一問(wèn)題,Tesla給出了一個(gè)很好的解決方案。
進(jìn)化一:多相機(jī)輸入
我們知道不能簡(jiǎn)單的單獨(dú)使用每個(gè)相機(jī)圖像的感知結(jié)果來(lái)進(jìn)行車輛的規(guī)劃控制,要精確的知道每個(gè)交通參與者的位置,道路的走向,需要車體坐標(biāo)下的感知結(jié)果。要達(dá)到這種效果有以下三種可能的方案:
方案1:在各相機(jī)上分別做感知任務(wù),然后投影到車體坐標(biāo)系下進(jìn)行整合;
方案2:將多個(gè)相機(jī)的圖像直接變換和拼接到車體坐標(biāo)系下,再在拼接后的圖像上做感知任務(wù);
方案3:直接端到端處理,輸入多相機(jī)圖像,輸出車體坐標(biāo)下的感知結(jié)果;
對(duì)于方案1,實(shí)踐發(fā)現(xiàn)效果不理想。比如圖4,圖像空間顯示很好的車道線檢測(cè)結(jié)果,投影到車體坐標(biāo)之后,就變得不太能用。
原因在于這種實(shí)現(xiàn)方式需要精確到像素級(jí)別的預(yù)測(cè), 才能夠比較準(zhǔn)確地將結(jié)果投影到車體坐標(biāo),而這一要求過(guò)于嚴(yán)苛。

圖4 圖像空間下很好的車道線結(jié)果在Vector Space下不太理想
另外在多相機(jī)的目標(biāo)檢測(cè)中,會(huì)遇到一些問(wèn)題,當(dāng)一個(gè)目標(biāo)同時(shí)出現(xiàn)在多個(gè)相機(jī)視野時(shí),投影到車體坐標(biāo)后會(huì)出現(xiàn)重影。此外,對(duì)于一些比較大的目標(biāo),一個(gè)相機(jī)的視野不足以囊括整個(gè)目標(biāo),每個(gè)相機(jī)都只能捕捉到局部,整合這些相機(jī)的感知結(jié)果就會(huì)變成非常困難。
對(duì)于方案2,圖像完美拼接本就是一件非常困難的事情,同時(shí)拼接還受到路平面、遮擋的影響。
于是Tesla最終選擇了方案3。方案3會(huì)面臨兩個(gè)問(wèn)題,一個(gè)是如何將圖像空間的特征轉(zhuǎn)換到車體坐標(biāo),另一個(gè)是如何獲得車體坐標(biāo)下的標(biāo)注數(shù)據(jù)。下面主要討論第一個(gè)問(wèn)題。
關(guān)于將圖像空間的到車體坐標(biāo)的特征轉(zhuǎn)換,Tesla使用一個(gè)Multi-Head Attention的transformer,來(lái)表示這個(gè)轉(zhuǎn)換空間,而將每個(gè)相機(jī)的圖像轉(zhuǎn)換為key和value。
這是一個(gè)很精妙的方案,完美地運(yùn)用了Transformer的特點(diǎn),將每個(gè)相機(jī)對(duì)應(yīng)的圖像特征轉(zhuǎn)換為Key和value,然后訓(xùn)練模型以查表的方式自行檢索需要的特征用于預(yù)測(cè)。
這樣的設(shè)計(jì)的好處是,無(wú)需顯式地在特征空間上做一系列幾何變換,也不受路平面等因素影響,很順暢的將輸入信息過(guò)渡到了車體坐標(biāo)。
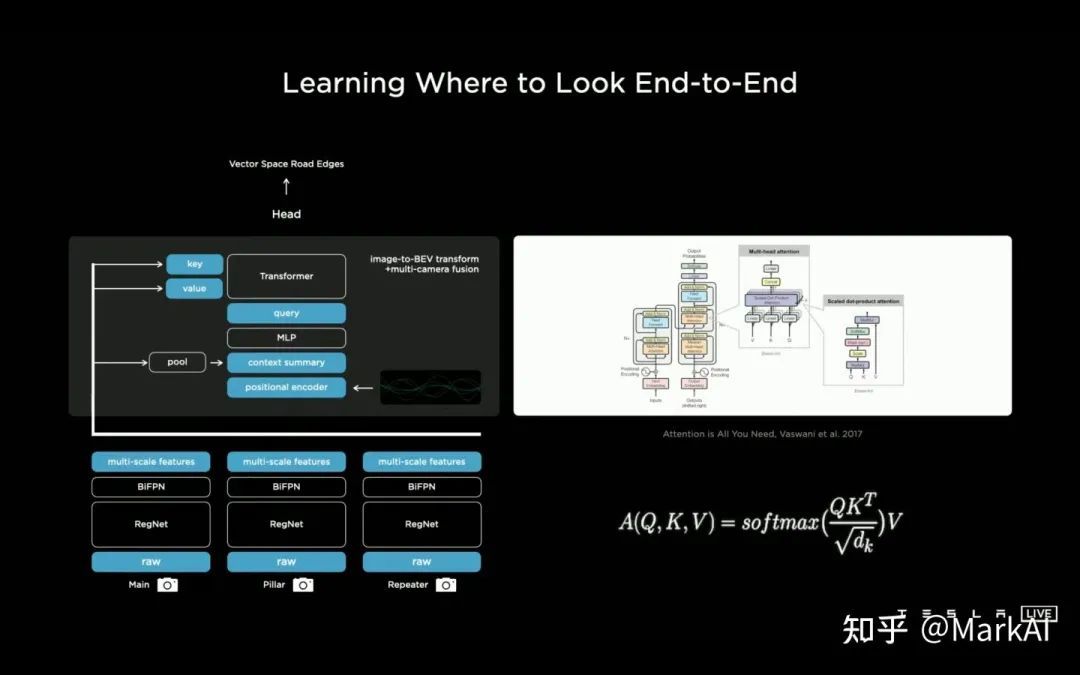
圖5 使用Transformer整合多相機(jī)信息
加入這一優(yōu)化后,車道線識(shí)別更加準(zhǔn)確清晰,目標(biāo)檢測(cè)的結(jié)果更加穩(wěn)定,同時(shí)不再有重影,效果如圖6所示。
圖6 使用Transformer整合多目信息后,感知效果明顯提升
進(jìn)化二:時(shí)間和空間信息
經(jīng)上述優(yōu)化后,感知模塊雖然可以在多相機(jī)輸入的情況下得到車體坐標(biāo)準(zhǔn)確且穩(wěn)定的預(yù)測(cè)結(jié)果,但是是針對(duì)單幀的處理,沒(méi)有時(shí)序信息。
而在自動(dòng)駕駛場(chǎng)景中,需要對(duì)交通參與者的行為進(jìn)行預(yù)判,同時(shí)視覺(jué)上的遮擋等情況需要結(jié)合多幀信息進(jìn)行處理,因此需要考慮時(shí)序信息。
為了解決此問(wèn)題,Tesla在網(wǎng)絡(luò)中添加了特征隊(duì)列模塊用于緩存時(shí)序上的特征,以及視頻模塊用來(lái)融合時(shí)序上的信息。此外,還給模型加入了IMU等模塊帶來(lái)的運(yùn)行學(xué)信息,比如車速和加速度。
經(jīng)上述處理后,在Heads中進(jìn)行解碼得到最終的輸出。
特征隊(duì)列模塊
特征隊(duì)列模塊將時(shí)序上多個(gè)相機(jī)的特征,運(yùn)動(dòng)學(xué)的特征,以及特征的position encoding concat到一起,處理后的特征將輸入至視頻模塊,如圖7所示。
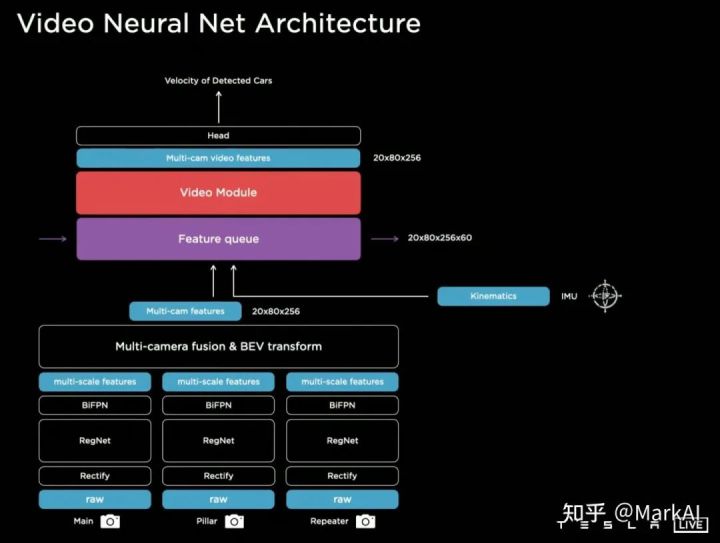
圖7 在模型中加入特征隊(duì)列,視頻模塊,以及運(yùn)動(dòng)信息作為進(jìn)一步優(yōu)化
特征隊(duì)列模塊按照隊(duì)列的數(shù)據(jù)結(jié)構(gòu)組織特征序列,其可分為時(shí)間特征隊(duì)列和空間特征隊(duì)列,如圖8所示。
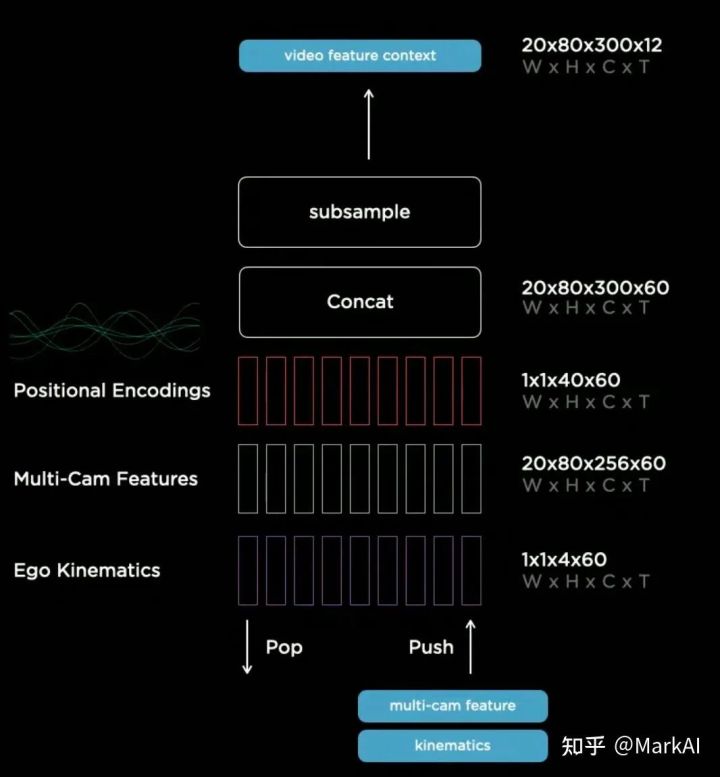
圖8 特征隊(duì)列
時(shí)序特征隊(duì)列:每隔27ms將一個(gè)新的特征加入隊(duì)列。時(shí)序特征隊(duì)列可以穩(wěn)定感知結(jié)果的輸出,比如運(yùn)動(dòng)過(guò)程中發(fā)生的目標(biāo)遮擋,模型可以找到目標(biāo)被遮擋前的特征來(lái)預(yù)測(cè)感知結(jié)果。
空間特征隊(duì)列:每前進(jìn)1m將一個(gè)新的特征加入隊(duì)列。主要用于需要長(zhǎng)時(shí)間靜止等待的場(chǎng)景,比如等紅綠燈之類。因?yàn)樵谠摖顟B(tài)下一段時(shí)間后,之前的時(shí)序特征隊(duì)列中的特征會(huì)因出隊(duì)而丟失。因此需要用空間特征隊(duì)列來(lái)記住一段距離之前路面的信息,包括箭頭、路邊標(biāo)牌等交通標(biāo)志信息。
上述的特征隊(duì)模塊僅用于增加時(shí)序信息,而視頻模塊主要用來(lái)整合這些時(shí)序信息。Tesla采用RNN結(jié)構(gòu)來(lái)作為視頻模塊,并將其命名為空間RNN模塊,如圖9所示。
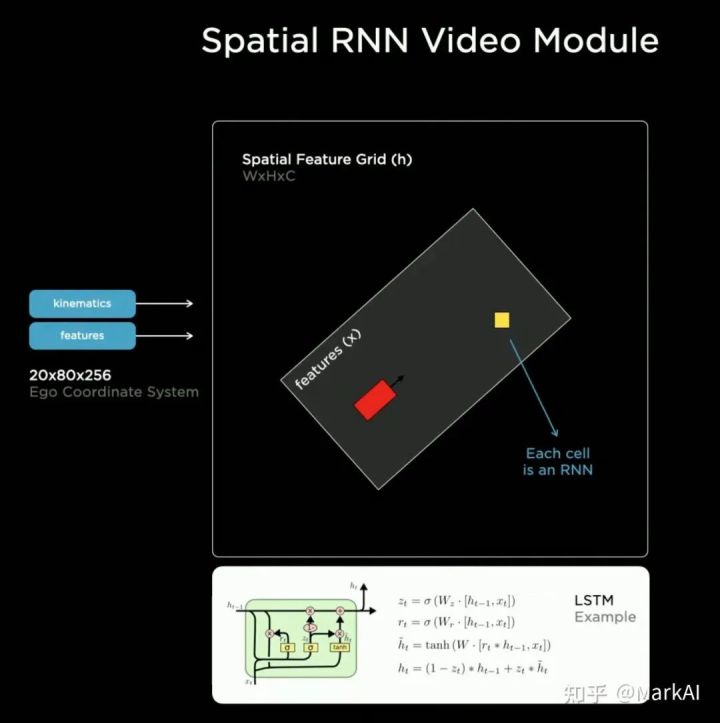
圖9 空間RNN作為視頻模塊
因?yàn)檐囕v在二維平面上前進(jìn),所以可以將隱狀態(tài)組織成一個(gè)2D的網(wǎng)格。當(dāng)車輛前進(jìn)時(shí),只更新網(wǎng)格上車輛附近可見(jiàn)的部分,同時(shí)使用車輛運(yùn)動(dòng)學(xué)狀態(tài)以及隱特征(hidden features) 更新車輛位置。
在這里,Tesla相當(dāng)于采用了一個(gè)2D的feature map作為局部地圖,在車輛前進(jìn)過(guò)程中,不斷根據(jù)運(yùn)動(dòng)學(xué)狀態(tài)以及感知結(jié)果更新這個(gè)地圖,避免因?yàn)橐暯呛驼趽鯉?lái)的不可見(jiàn)問(wèn)題。同時(shí)在此基礎(chǔ)上,可以添加一個(gè)Head用來(lái)預(yù)測(cè)車道線,交通標(biāo)志等,以構(gòu)建高精地圖。
通過(guò)可視化該RNN的feature,可以更加明確該RNN具體做了什么:不同channel分別關(guān)注了道路邊界線、車道中心線、車道線、路面等等,如圖10所示。
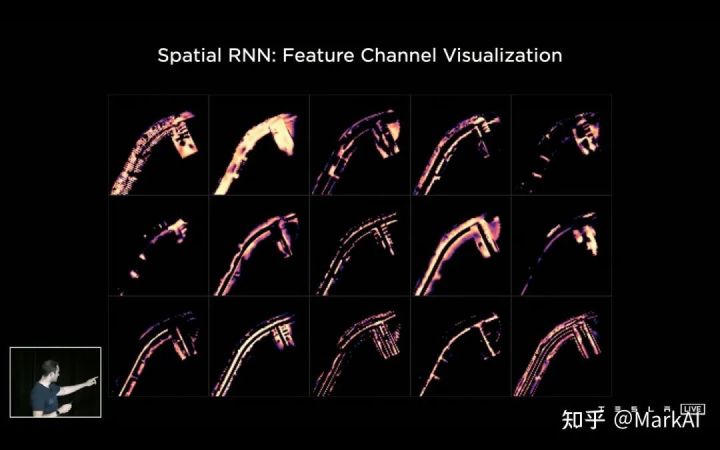
圖10 空間RNN學(xué)到的特征可視化
添加了視頻模塊后,能夠提升感知系統(tǒng)對(duì)于時(shí)序遮擋的魯棒性,以及對(duì)于距離和目標(biāo)移動(dòng)速度估計(jì)的準(zhǔn)確性,如圖11所示。
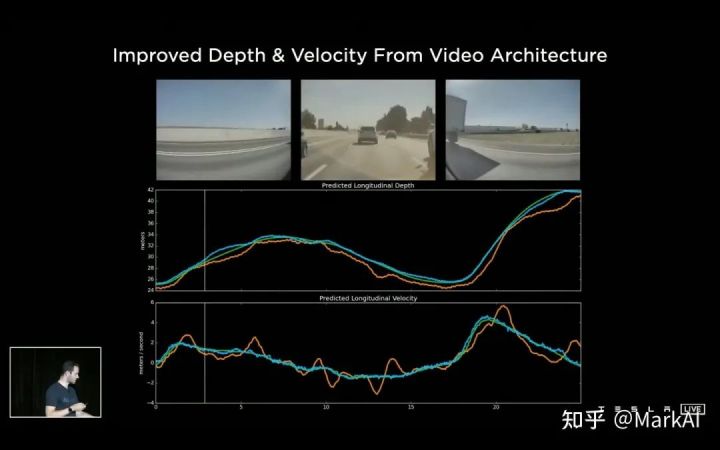
圖11 加入視頻模塊可以改善對(duì)目標(biāo)距離和運(yùn)動(dòng)速度的估計(jì),綠線為激光雷達(dá)的GT,黃線和藍(lán)線分別為加入視頻模塊前后模型的預(yù)測(cè)值
最終的模型
在初版HydraNet的基礎(chǔ)上,使用Transformer整合了多個(gè)相機(jī)的特征,使用Feature Queue維護(hù)一個(gè)時(shí)序特征隊(duì)列和空間特征隊(duì)列,并且使用Video Module對(duì)特征隊(duì)列的信息進(jìn)行整合,最終接上HydraNet各個(gè)視覺(jué)任務(wù)的Head輸出各個(gè)感知任務(wù)。
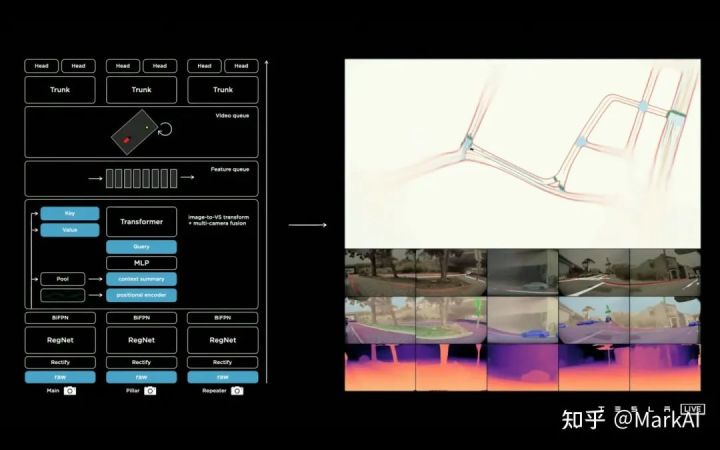
圖13 最終完整的模型結(jié)構(gòu)以及對(duì)應(yīng)感知結(jié)果
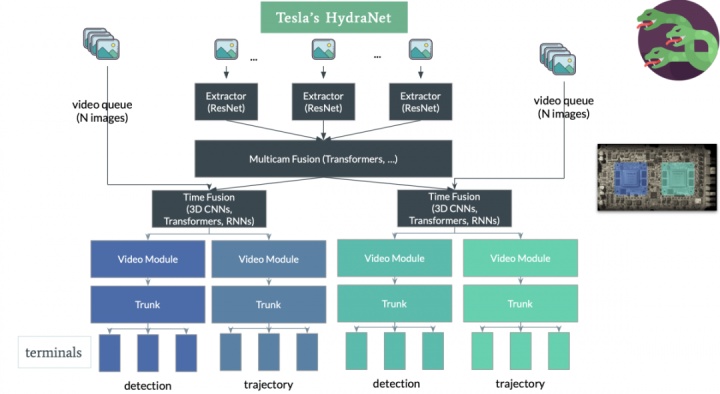
圖12 最新HydraNet模型結(jié)構(gòu)
最新的HydraNet模型如圖13所示,簡(jiǎn)單展示了圖像提取、多相機(jī)圖像融合、時(shí)間融合,以及最后拆分為不同的HEAD。
整個(gè)感知系統(tǒng)使用一個(gè)模型進(jìn)行整合,融合了多個(gè)相機(jī)時(shí)序上和空間上的信息,最終直接輸出所有需要的感知結(jié)果,一氣呵成,非常干凈和優(yōu)雅,可以當(dāng)做教科書一般。
贊嘆該系統(tǒng)的精妙之外,也可以看到Tesla團(tuán)隊(duì)強(qiáng)大的工程能力,背后強(qiáng)大的算力和數(shù)據(jù)標(biāo)注系統(tǒng)是支持這一切的前提,當(dāng)然,那啥,本質(zhì)上還是有錢啦……
此外,該系統(tǒng)也并不是最終版的自動(dòng)駕駛感知系統(tǒng),還會(huì)一直不斷迭代升級(jí),國(guó)內(nèi)的同行們要加油了?。?
點(diǎn)贊 0 反對(duì) 0 舉報(bào) 0
收藏 0
評(píng)論 0 分享 46



 廣告
廣告 編輯推薦




最新資訊
-
聯(lián)合國(guó)法規(guī)R60對(duì)兩輪車操縱件與指示裝置的
2026-03-04 12:08
-
標(biāo)準(zhǔn)立項(xiàng)|《汽車異種材料鉚接接頭拉伸性能
2026-03-04 11:40
-
“汽車大角度座椅 第1部分:通用要求”將有
2026-03-04 11:39
-
“汽車大角度座椅 第2部分:可靠性要求”將
2026-03-04 11:39
-
電池耐久評(píng)價(jià)開始從“電池單體性能指標(biāo)”轉(zhuǎn)
2026-03-04 11:38
